Metabolomic data is usually high dimensional, in the sense that the features, or variables, outnumber the observations – in this case, a few hundred samples, with tens of thousands of metabolites per sample - a phenomenon commonly referred to as the “curse of dimensionality”1. For this reason, we employed a gradientboosting decision tree (GBDT) model, since this type of algorithm tends to perform well even in very-high-dimensional scenarios2. In addition to the above, GBDT models are also robust to feature scaling and multicollinearity between features, and enjoy a high level of popularity due to their efficiency and state-of-the-art performance, as well as the availability of fast, easy-to-use implementations. Here, we worked with the Python implementation of Microsoft’s LightGBM3.
One disadvantage of GBDT models, compared to e.g. logistic regression, is that they are not directly interpretable. Therefore, in order to determine which metabolites have a larger influence in driving the model’s prediction, we decided to use a recently-developed feature attribution method: SHapley (Shapley Additive exPlanations) values, rooted in game theory, which provide per sample explanations which are proven to be both consistent and locally accurate, as opposed to the built-in feature importance measures of GBDT models4.
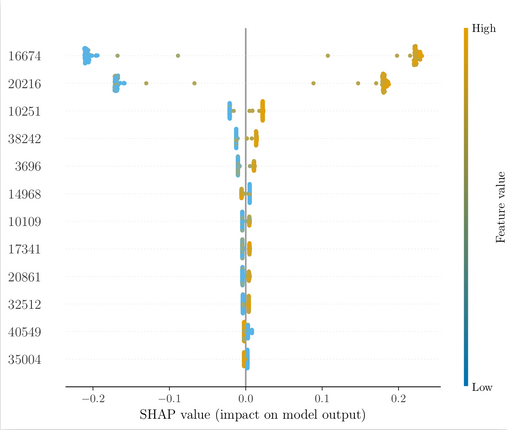
This was carried out using the tree ensemble implementation of the shap Python package5, and an example of the results is shown in the figure below: the values themselves correspond to the change in log-odds of the sample being classified as corresponding to one or the other genus – in this case, a positive value indicates a larger probability of being Xenorhabdus – relative to the mean prediction upon addition of a given feature, effectively measuring the impact that every single feature value has on every single sample – the variable names signify the numerical ID of each different metabolite.
Nicholas Tobias, Cesar Parra-Rojas, Yan-Ni Shi, Yi-Ming Shi, Svenja Simonyi, Aunchalee Thanwisai, Apichat Vitta, Narisara Chantratita, Esteban A Hernandez-Vargas, Helge B Bode. Focused natural product elucidation by prioritizing high-throughput metabolomic studies with machine learning. BioRxiv, 2019.
References:
1. Verleysen M., François D. (2005) The Curse of Dimensionality in Data Mining and Time Series Prediction. In: Cabestany J., Prieto A., Sandoval F. (eds) Computational Intelligence and Bioinspired Systems. IWANN 2005. Lecture Notes in Computer Science, vol 3512. Springer, Berlin, Heidelberg
2. Nielsen, D. (2016). Tree Boosting With XGBoost-Why Does XGBoost Win" Every" Machine Learning Competition? (Master's thesis, NTNU).
3. Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., ... & Liu, T. Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. In Advances in Neural Information Processing Systems (pp. 3146-3154). GitHub repository: github.com/microsoft/lightgbm
4. Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems (pp. 4765-4774).